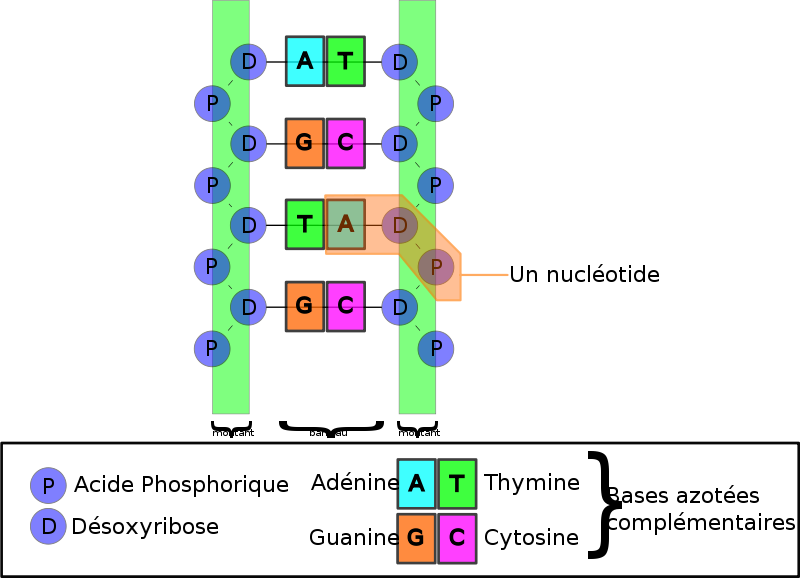
La séquence d’ADN d’un gène détermine la séquence d’acides aminés de la protéine qu’il code. Dans la région codant pour les protéines d’un gène, la séquence d’ADN est interprétée en groupes de trois bases nucléotidiques, appelés codons. Chaque codon spécifie un seul acide aminé dans une protéine.
En bref : Le code génétique et la lecture des gènes
- La lecture d’un gène se fait par groupes de trois bases nucléotidiques, appelés codons.
- Le code génétique est le manuel d’instructions universel qui associe chaque codon à un acide aminé.
- Le codon de départ (ATG) et les codons stop indiquent où commence et où se termine la séquence d’une protéine.
- Les mutations, qu’elles soient ponctuelles ou par insertion/suppression, peuvent altérer la lecture d’un gène et la protéine finale.
L’ADN en tant que phrase
On peut considérer la séquence de codage des protéines d’un gène comme une phrase composée entièrement de mots de 3 lettres. Dans la séquence, chaque mot de 3 lettres est un codon, spécifiant un seul acide aminé dans une protéine. Jetez un coup d’œil à cette phrase :
Lesdésontétémissuruneclé
Si vous deviez diviser cette phrase en mots de 3 lettres, vous la liriez probablement comme ceci :
Les dés ont été mis sur une clé
Cette phrase représente un gène. Chaque lettre correspond à une base nucléotidique, et chaque mot représente un codon. Et si vous changiez la manière de lire en faisant d’autre découpages ? Vous vous retrouveriez avec :
Le sdé son tété mis suru neclé ou encore L esd és ont étém issu run eclé
Comme vous pouvez le constater, une seule manière de découper ces mots permet de faire phrase compréhensible. De la même manière, il n’y a qu’une seule façon de lire un gène pour qu’il code la bonne protéine.
Comment les cellules lisent un gène ?
Prenez cette séquence d’ADN :
GCATGCTCTGCTGCGAAACTTTTTGGCTGA
Vous pouvez séparer la séquence en codons de 3 lettres, de 3 façons différentes :
GCA TGC TGC TGC GAA ACT TTG TTG GCT GA
G CAT GCT GCT GCG AAA CTT TGG TGG CTG A
GC ATG CTG CTG CGA AAC TTT GGC TTT GGC TGA
Comment savoir de quelle manière les lire et comment trouver la bonne manière de les lire ?
Toutes les régions codant pour les protéines commencent par la séquence « ATG », qui code pour la méthionine (Met), un acide aminé. Par conséquent, le cadre de lecture correct contiendra le codon « ATG. »
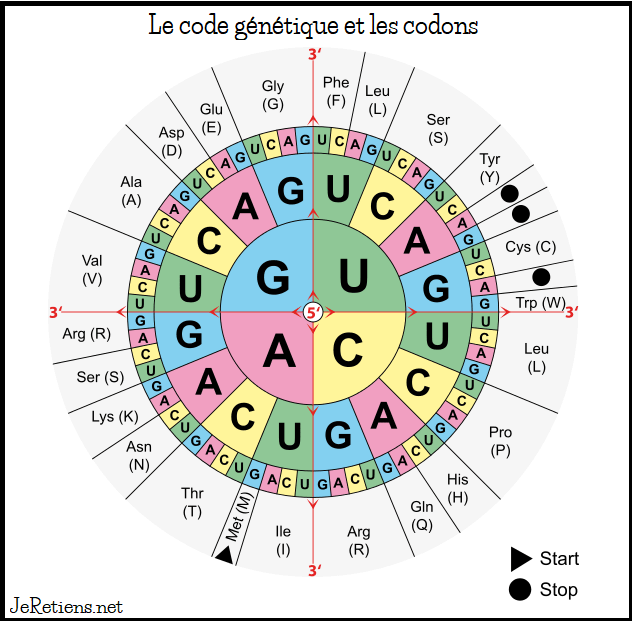
Vous pouvez prédire la séquence d’acides aminés de la protéine en utilisant le code génétique.
Le code génétique
Le code génétique est le manuel d’instructions que toutes les cellules utilisent pour lire la séquence d’ADN d’un gène et construire une protéine correspondante. Les protéines sont composées d’acides aminés qui s’enchaînent en une chaîne. Chaque séquence d’ADN de 3 lettres, ou codon, code un acide aminé spécifique.
Le code a plusieurs caractéristiques principales :
- Toutes les régions de codage des protéines commencent par le codon de départ, ATG.
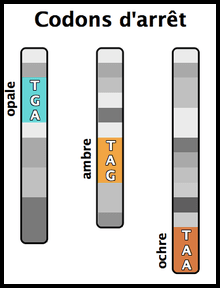
- Il y a trois codons « stop » qui marquent la fin de la région de codage des protéines : UAA (ocre), UAG (ambre) et UGA (opale).
- Plusieurs codons peuvent coder pour le même acide aminé.
L’impact d’une mutation sur un gène
La mutation est un processus qui modifie de façon permanente une séquence d’ADN. Changer la séquence d’ADN d’un gène peut changer la séquence d’acides aminés de la protéine qu’il code.
Mutations ponctuelles
Les mutations ponctuelles sont des changements de base uniques dans la séquence d’ADN d’un gène. Elles peuvent être catégorisées plus en détail :
- Les mutations malencontreuses provoquent un seul changement d’acide aminé dans la protéine.
- Des mutations absurdes créent un codon « stop » prématuré qui raccourcit la protéine.
- Les mutations silencieuses ne causent pas de changements d’acides aminés.
Mutations d’insertion et de suppression
Les mutations d’insertion et de suppression ajoutent ou suppriment une ou plusieurs bases d’ADN. Les insertions et les délétions (à moins qu’elles ne se produisent par multiples de 3) peuvent déplacer le cadre de lecture d’un gène, modifiant le groupement des bases en codons. Aussi appelées mutations de décalage de trames, ces changements peuvent grandement affecter la séquence d’acides aminés d’une protéine.
Conclusion
La lecture d’un gène est un processus d’une précision remarquable, comparable à la lecture d’une phrase où un seul découpage est le bon. Cette lecture s’opère grâce au code génétique, un ensemble de règles universelles qui traduisent les codons de l’ADN en acides aminés pour former les protéines. Un simple changement, ou mutation, peut avoir des conséquences profondes, altérant la protéine finale. La compréhension de ce mécanisme fondamental est essentielle pour saisir les bases de la biologie moléculaire, de la génétique et de leurs implications dans la santé et les maladies.
FAQ : Le code génétique et les mutations
Qu’est-ce qu’un codon ?
Un codon est une séquence de trois bases nucléotidiques sur l’ADN (ou l’ARN) qui spécifie un acide aminé particulier ou un signal de « départ » ou de « stop » pour la synthèse d’une protéine.
Quel est le rôle du code génétique ?
Le code génétique est le manuel d’instructions universel utilisé par les cellules pour traduire la séquence de l’ADN en une séquence d’acides aminés, permettant ainsi la fabrication des protéines.
Qu’est-ce qu’un codon de départ ?
Le codon de départ, qui est presque toujours ATG, marque le début de la séquence d’un gène à lire pour synthétiser une protéine. Il code pour l’acide aminé méthionine.
Qu’est-ce qu’un codon stop ?
Les codons stop, au nombre de trois (UAA, UAG, UGA), signalent la fin de la traduction d’une séquence génétique. Ils ne codent pour aucun acide aminé et terminent la synthèse de la protéine.
Qu’est-ce qu’une mutation génétique ?
Une mutation génétique est un changement permanent dans la séquence d’ADN d’un gène. Elles peuvent être spontanées ou causées par des facteurs externes et peuvent avoir un impact sur la fonction de la protéine codée.
Quelle est la différence entre une mutation ponctuelle et une mutation par insertion/suppression ?
Une mutation ponctuelle affecte une seule base de l’ADN, tandis qu’une mutation par insertion ou suppression ajoute ou retire une ou plusieurs bases, ce qui peut décaler le cadre de lecture du gène.
Qu’est-ce qu’une mutation de décalage de trame ?
Une mutation de décalage de trame, ou mutation par décalage de cadre de lecture, se produit lorsque des bases sont ajoutées ou retirées en dehors de multiples de trois, modifiant ainsi tous les codons suivants et altérant potentiellement la totalité de la protéine.
Qu’est-ce qu’une mutation silencieuse ?
Une mutation silencieuse est un type de mutation ponctuelle qui ne change pas l’acide aminé final. Cela est possible car plusieurs codons peuvent coder pour le même acide aminé. Elle n’a donc pas d’impact visible sur la protéine.
Comment se fait la lecture d’un gène ?
La lecture d’un gène est un processus très précis, car il n’y a qu’un seul cadre de lecture correct qui commence au codon de départ (ATG) et se termine au codon stop, produisant ainsi la protéine fonctionnelle attendue.
Le code génétique est-il le même pour tous les êtres vivants ?
Le code génétique est considéré comme universel, ce qui signifie que presque tous les organismes vivants utilisent le même code pour traduire leurs gènes en protéines. Il existe quelques légères variations, mais la structure de base est la même pour les bactéries, les plantes et les animaux.
Les mutations sont-elles toujours négatives ?
Non, les mutations ne sont pas toujours négatives. Certaines peuvent être neutres (mutations silencieuses) ou, plus rarement, être bénéfiques, en apportant de nouvelles caractéristiques qui favorisent l’adaptation et l’évolution d’une espèce.
Pourquoi l’ADN est-il considéré comme une « phrase » ?
On peut considérer l’ADN comme une phrase car, comme une phrase qui a un début, une fin, des mots de taille fixe (les codons) et un sens de lecture unique pour être compréhensible, un gène possède un codon de départ, un codon stop, et une lecture spécifique qui détermine la protéine finale.
Quel lien y a-t-il entre l’ADN et les protéines ?
L’ADN contient les instructions génétiques pour fabriquer les protéines. Ces instructions sont d’abord transcrites en ARN messager, puis l’ARN est traduit en une chaîne d’acides aminés qui se replie pour former une protéine fonctionnelle.
Pourquoi est-il important de comprendre le code génétique ?
La compréhension du code génétique est fondamentale pour la génétique et la médecine. Elle permet de comprendre les maladies génétiques, de développer de nouvelles thérapies et de progresser dans la recherche sur l’évolution et les relations entre les espèces.

Rejoignez-nous sur Instagram !
Découvrez nos infographies et astuces : @JeRetiensNet