Assis à une terrasse, vous sentez votre téléphone vibrer. « Pluie intense dans 12 minutes ». À peine le temps de glisser à votre voisin : « Pff, ils se trompent toujours. » Vous haussez les épaules… lorsqu’une goutte vous tombe sur le nez. L’IA ricane.
Depuis toujours, l’être humain a tenté de prédire des événements à partir d’observations présentes et passées. Ainsi, nous avons tous entendu de nos grands-parents des bribes de sagesse populaire telles que : « Un vent froid s’est levé, il ne va pas tarder à pleuvoir. »
Remplacez maintenant les sens d’une personne et la mémoire d’un village par une intelligence artificielle capable d’ingérer une quantité astronomique de données et d’images sur de vastes périodes… Pourra‑t‑elle vraiment nous dire s’il pleuvra dans 12 minutes ? Et en quelle quantité ?
En bref
Le machine learning révolutionne la prévision météo en permettant aux systèmes d’apprendre de millions de données passées. Cet article explore les trois types d’apprentissage (supervisé, non supervisé et par renforcement) et leurs applications concrètes pour affiner les prévisions, détecter les anomalies ou optimiser des ressources face aux caprices du ciel. Malgré des limites liées à l’incertitude et aux coûts, l’IA ne remplace pas l’expert mais augmente ses capacités, menant vers une « météo augmentée » de plus en plus précise.
Qu’est‑ce que le machine learning ?
Le machine learning ou, en bon français, l’apprentissage automatique, est une branche de l’intelligence artificielle qui donne aux machines la capacité d’apprendre.
Concrètement, le modèle logiciel doit extraire des conclusions ou formuler des prédictions à partir de données observées. L’idée est donc de remplacer une liste de règles écrites à la main par un modèle qui découvre lui‑même des régularités cachées.
On distingue trois grands modes d’apprentissage.
1. Apprentissage supervisé

Chaque exemple d’entrée est accompagné de la « bonne » réponse : quantité de pluie, prix d’une course, diagnostic médical… Le modèle ajuste alors ses paramètres pour réduire l’erreur entre sa prédiction et la valeur réelle.
Illustration intuitive. On vous propose la série : 2, 5, 11, 23, 47, …
Vous cherchez la règle : 2 → 5 ? 2 × 2 = 4, il manque +1. Hypothèse : (n × 2) + 1.
- (2 × 2) + 1 = 5
- (5 × 2) + 1 = 11
- (11 × 2) + 1 = 23
- (47 × 2) + 1 = 95.
Le modèle supervisé généralise ce principe à des millions d’exemples et à des millions de paramètres continus, cherchant à minimiser l’erreur moyenne, c’est‑à‑dire l’écart entre la bonne réponse et le résultat de son calcul. En pratique, viser zéro reste illusoire, car il n’existe pas toujours de formule exacte capable d’annuler totalement cette erreur.
Questions typiques : « Quelle quantité de pluie tombera ? », « Combien coûtera mon trajet ? »
2. Apprentissage non supervisé

Ici, aucune réponse n’est fournie ; l’algorithme repère tout seul des structures naturelles.
Imaginez un panier de chaussettes dépareillées renversé sur la table : vous regroupez spontanément les blanches, les rayées, celles à pois.
| Étape | Version algorithmique | Résultat |
| Observer chaque tas | Calcul du centre (le « prototype ») de chaque groupe. | Carte simplifiée du jeu de données, comptage des profils dominants. |
| Nommer les tas | Ajout d’une étiquette parlante par le data scientist. | Résultat compréhensible pour tous. |
| Ranger les nouvelles chaussettes | Affectation de chaque nouvel échantillon au groupe le plus proche. | Classification automatique sans étiquetage exhaustif. |
| Repérer l’intruse | Signalement d’une anomalie (outlier). | Détection de phénomènes rares. |
| Adapter l’action | Décision différente selon le groupe. | Outil d’aide à la décision. |
Questions typiques : « Quel type de temps observe‑t‑on ? », « Va‑t‑il pleuvoir demain ? »
3. Apprentissage par renforcement
Si, comme moi, vous avez eu l’occasion de faire ample connaissance avec les pics au sol dans le jeu vidéo Prince of Persia, vous ressentez déjà l’apprentissage par renforcement : avancer, échouer, recevoir un signal (positif ou négatif), ajuster sa stratégie, recommencer.
Dans Prince of Persia, chaque pas est une action ; l’écran qui s’effondre ou la porte qui s’ouvre sert de récompense (pénalité ou bonus). Le héros répète le chemin qui rapporte le plus de points et évite les détours fatals.

Un système de machine learning fait la même chose :
- Agent : le programme qui décide.
- Environnement : le monde dans lequel il évolue (jeu, usine, atmosphère).
- Action : un pas, un réglage, un clic.
- Récompense : score à maximiser (vies, coût, précision).
- Politique : stratégie affinée au fil des parties.
| Contexte | Action testée | Signal de récompense | Finalité |
| Trajet de camion | Choisir la route A, B ou C (pluie, vent, brouillard). | +1 si ponctuel & sobre ; −1 sinon. | Livrer à l’heure en économisant du diesel. |
| Éclairage urbain | Régler les lampadaires minute par minute. | +1 si visibilité ok & conso min. | Réduire la facture sans sacrifier la sécurité. |
| Irrigation | Lancer ou retarder l’arrosage. | +1 par litre d’eau économisé. | Économiser l’eau sans stress hydrique. |
| Patinoire extérieure | Ajuster la réfrigération. | +1 si glace < −5 °C & conso min. | Surface parfaite, coût réduit. |
| Vol long‑courrier | Changer altitude / route. | +1 confort + kérosène ; −1 détour inutile. | Moins de turbulence, moins de carburant. |
Dans chacun de ces cas :
- Essai‑erreur : l’algorithme teste différentes options.
- Récompense chiffrée : ponctualité, consommation, confort, etc.
- Amélioration continue : après des centaines de « parties », la politique optimale émerge — exactement comme vous mémorisez où ne pas sauter dans Prince of Persia.
La météo : un terrain de jeu idéal pour le machine learning
Aujourd’hui, nous disposons d’archives publiques gigantesques : observations in situ, images radar, données satellitaires, etc.
- Des dizaines de milliers de stations au sol (température, pression, humidité) minute par minute.
- Radars météo balayant l’atmosphère toutes les 30–60 s (5 min en routine).
- Satellites géostationnaires offrant une image toutes les 10–15 min (jusqu’à 1 min dans certains cas).
- Modèles numériques générant des téra‑octets de prévisions quotidiennes.
Cette avalanche de données dépasse largement ce qu’un humain peut analyser. C’est là que le machine learning intervient : non pour remplacer le météorologue (son expertise reste cruciale), mais pour lui fournir des outils statistiques. L’algorithme digère la masse de données, repère les motifs invisibles et produit des indices précis, jusqu’à l’averse de quartier ou à la chute de neige qui décalera un vol. La physique n’est pas évacuée ; elle est, au contraire, augmentée par ces nouvelles méthodes.
Supervisé, pour des prévisions « millimétrées »
Passons maintenant aux applications concrètes de chaque type d’apprentissage, en commençant par le supervisé.
Exercice pratique, un petit modèle maison qui tente de déterminer la probabilité de pluie un jour donné.
En quelques heures de programmation en Python, il a déjà été possible de produire un petit modèle simple pour déterminer les chances de pluie pour un jour donné.
Le modèle a été entraîné sur 5 ans d’archives d’observations récupérées via l’API du site open-meteo.com. Voici ce que nous pouvons en tirer.
| Indicateurs | Formule | Valeur | Lecture |
| Accuracy | (TN+TP)/N | 0,71 | environ 7 prédictions sur 10 sont correctes. |
| Précision | TP/(TP+FP) | 0,75 | Quand le modèle annonce la pluie, il a raison ~75 % du temps. |
| Recall (sensibilité) | TP/(TP+FN) | 0,81 | Il détecte ~81 % des pluies réelles. |
| F1‑score | Moyenne harm. précision/recall | 0,78 | Bon compromis entre fausses alertes et pluies ratées. |
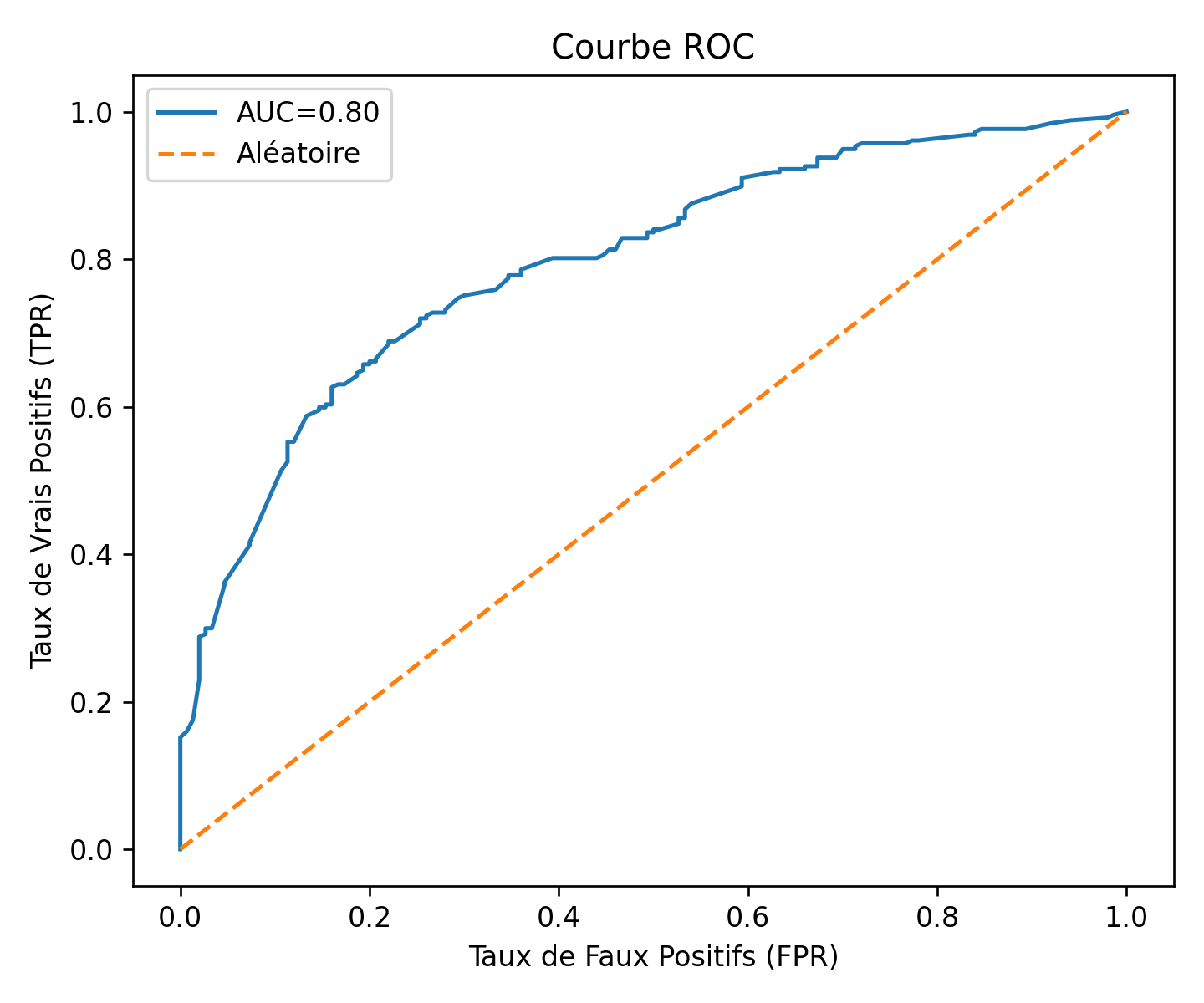
| AUC ROC | aire sous la courbe ROC | 0,80 | Capacité de classement correcte : 80 % de chances de classer une journée pluvieuse au‑dessus d’une journée sèche. |
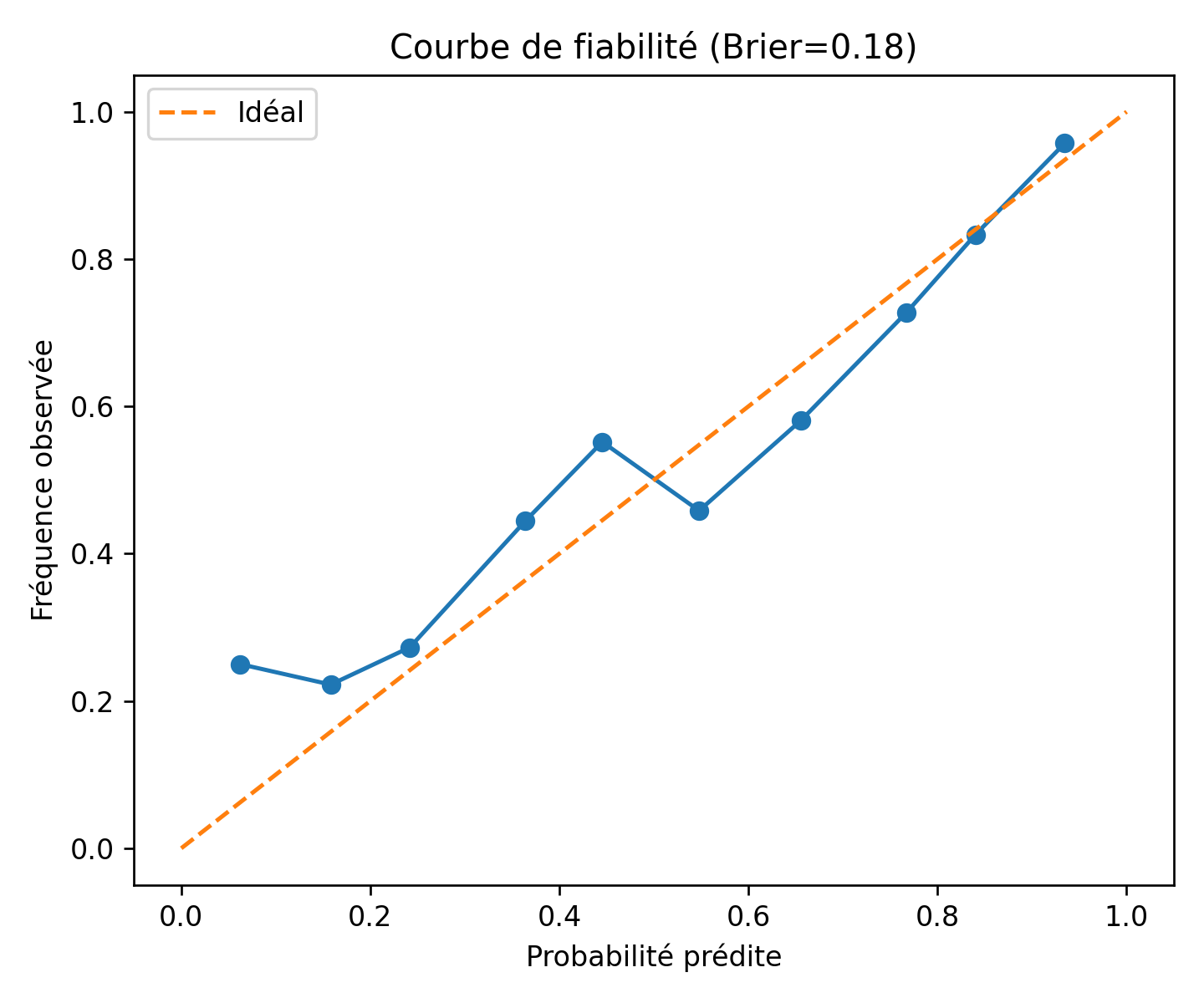
| Brier | erreur quadratique moyenne des probabilités annoncées | 0,18 | Probabilités globalement bien calibrées (plus c’est petit, mieux c’est). |
| Jeu de données | Modèle | Métriques globales* |
| Archives d’observation depuis le 01/01/2020 (source open‑meteo.com) | Régression logistique binaire + calibration isotone | AUC = 0 ,80
Brier = 0 ,18 · Précision = 0 ,75 Recall = 0 ,81 |
En clair : en quelques heures de code Python, on obtient déjà une prévision probabiliste crédible ; il suffit d’ajuster le seuil (ou d’enrichir les variables) pour réduire soit les fausses alertes, soit les pluies ratées, selon l’usage.
Pensez à notre question initiale : « Pourra-t-elle vraiment nous dire s’il pleuvra dans 12 minutes? Et en quelle quantité? » C’est exactement le type de problème que l’apprentissage supervisé excelle à résoudre en météo. Les données d’entrée sont toutes ces observations passées (température, humidité, pression, images radar, etc.) et la « bonne réponse » associée est… la quantité de pluie réellement tombée ou l’occurrence d’un orage à tel endroit, à tel moment après la prévision.
Les modèles sont entraînés sur des millions de ces scénarios passés. Ils apprennent à identifier des schémas dans la combinaison de ces facteurs qui mènent à un événement météo précis. Par exemple, une certaine évolution des échos radar, combinée à une humidité de l’air élevée et une pression en baisse, pourrait être un signal très fiable de pluie imminente. Le modèle apprend à pondérer l’importance de chacun de ces signaux bien mieux qu’une simple liste de règles « si-alors » écrites par un expert.
Les applications sont déjà concrètes :
- Prévisions à très court terme (nowcasting) : anticiper précisément l’arrivée et l’intensité d’une averse dans les prochaines minutes à l’échelle d’un quartier. C’est ce qui vous avertit sur votre téléphone que la pluie arrive dans 12 minutes !
- Détection d’événements extrêmes : identifier les signaux faibles précurseurs de tempêtes violentes, de grêle, ou de tornades, en analysant des flux de données en temps réel.
- Correction des modèles numériques : les supercalculateurs génèrent des prévisions, mais le ML peut « affiner » ces prévisions en apprenant des erreurs passées des modèles eux-mêmes, les rendant encore plus précises.
Non supervisé : débusquer l’invisible
Et notre panier de chaussettes dépareillées dans tout ça ? En météo, l’apprentissage non supervisé est fantastique pour explorer des données sans a priori, pour trouver des « chaussettes qui vont ensemble » là où l’œil humain ne verrait qu’un fouillis.
Par exemple, il peut :
- Identifier des « régimes météorologiques » : sans qu’on lui dise, le modèle peut regrouper des milliers de situations atmosphériques passées en quelques grands « types » de temps (par exemple, un type « anticyclonique stable et chaud », un type « perturbé avec dépressions atlantiques », etc.). Cela aide les météorologues à mieux comprendre les dynamiques à grande échelle et à affiner leurs prévisions sur le long terme.
- Détecter des anomalies climatiques : un schéma de températures ou de précipitations qui ne « ressemble » à aucun des groupes habituels ? C’est peut-être un signal précoce d’un changement climatique ou d’un événement rare.
- Compresser des données massives : les modèles météo génèrent tellement de données qu’il est difficile de les stocker et de les analyser. Le ML non supervisé peut aider à résumer ces données en conservant l’information essentielle, rendant l’analyse plus rapide.
Renforcement : décisions météo intelligentes
L’apprentissage par renforcement, avec son agent qui apprend par essai-erreur comme Prince of Persia, est peut-être le plus futuriste en météo, mais son potentiel est immense pour l’aide à la décision.
Reprenons les exemples donnés plus haut :
- Gestion des ressources en eau : Un système basé sur le renforcement pourrait apprendre à optimiser l’ouverture et la fermeture des vannes de barrages, non seulement en fonction des prévisions de pluie, mais aussi de l’état des sols, des besoins en irrigation et de la consommation d’eau potable. La « récompense » serait la maximisation des réserves tout en évitant les inondations ou les pénuries.
- Optimisation du réseau électrique : En cas de vague de chaleur, la consommation d’électricité explose avec la climatisation. Un agent de renforcement pourrait apprendre à allumer et éteindre des centrales, ou à stocker de l’énergie, en fonction des prévisions de températures et de consommation, afin de minimiser les coûts et le risque de black-out. La récompense serait un équilibre optimal entre l’offre et la demande, avec le moins de dépense énergétique.
- Planification logistique urbaine : Un système pourrait ajuster les itinéraires des véhicules de livraison en temps réel, non seulement pour éviter les embouteillages, mais aussi pour anticiper ceux causés par une forte pluie ou un vent violent, en minimisant le temps de trajet et la consommation de carburant.
Limites et défis
- Incertitude : même le modèle le plus affûté ne livre qu’une probabilité, jamais une promesse. Ses sorties s’expriment en pourcentages ou en intervalles de confiance ; c’est au décideur de transformer ce risque chiffré en action concrète.
- Biais de données : capteur mal calibré, région mal couverte ou historique tronqué : autant d’angles morts qui peuvent entraîner l’algorithme sur la mauvaise pente, rendant les prévisions plus fragiles sur les océans, en montagne ou dans les pays sous‑instrumentés.
- Coût énergétique : entraîner un réseau profond pendant 48 h sur une ferme de GPU peut engloutir l’équivalent d’une semaine d’électricité pour un foyer européen
- Complémentarité : la circulation atmosphérique obéit toujours aux équations de la physique. Le ML agit comme une loupe statistique ; il affine, corrige et accélère, mais ne remplace ni la dynamique des fluides (ce dont tient compte un modèle météorologique classique) ni l’œil expert du météorologue.
Notre petit modèle et ses limites
| Limites | Ce que montre le prototype | Pourquoi c’est un défi | Pistes d’amélioration |
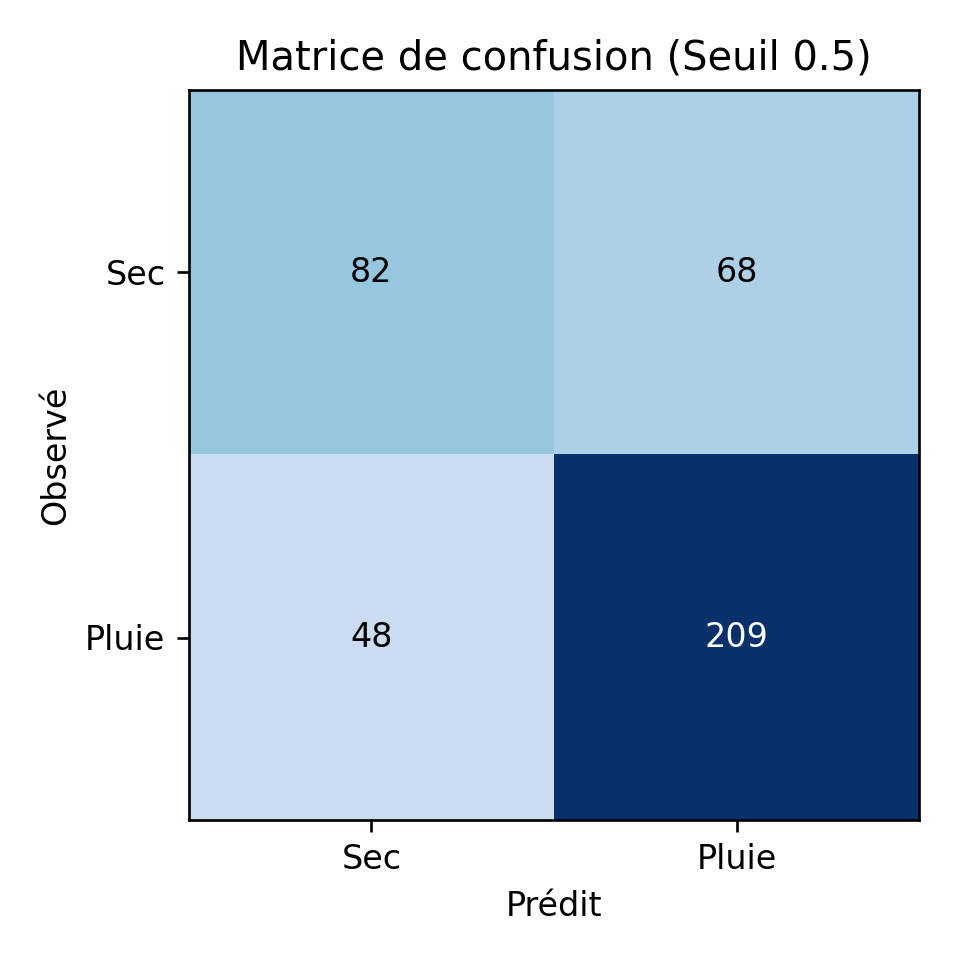
| Incertitude (probabilité ≠ certitude) | AUC 0,80 mais 48 pluies manquées / 68 fausses alertes | Dans la pratique, on doit souvent se prononcer par un simple « alerte » ou « pas d’alerte » ; le réglage est délicat, car une alerte manquée peut avoir des conséquences graves pour la population, tandis qu’une fausse alerte finit par user la confiance du public. | Adapter le seuil selon le contexte (une fausse alerte vaut souvent mieux que pas d’alerte) ,combiner avec le radar temps réel, un modèle physique traditionnel,… |
| Coût énergétique | Entraînement sur laptop prend quelques secondes, mais une version deep learning demanderait des jours de calculs | Un modèle plus complexe donne une précision mais augmente les coûts. | Nombreuses pistes à l’étude: alléger le modèle (l’élaguer ou le compresser), l’exécuter sur un cloud alimenté par des énergies vertes, ou le faire tourner directement sur de petits ordinateurs embarqués proches des capteurs. |
| Complexité physique | Notre prototype exploite les variables de surface (dites 2‑D : pression, humidité, vent au sol), mais il ignore encore les variables 3‑D qui varient aussi avec l’altitude, p.ex. la mécanique interne des nuages d’orage, un phénomène complexe qui exige des modèles physiques lourds. | On a toujours besoin des équations physiques (Navier-Stokes) pour décrire les mouvements de l’air, y compris les phénomènes à petite échelle comme la turbulence. | Coupler ML + modèle numérique (hybride) plutôt que remplacer. |
| Éthique & alarme | 68 fausses alertes -> lassitude possible | Trop d’alertes = utilisateurs ignorent le système | Seuil adaptatif : seuil haut pour notification push, seuil bas pour info discrète. |
Questions fréquentes sur le Machine Learning et la Météo (FAQ)
Qu’est-ce que le machine learning en prévision météo ?
Le machine learning (apprentissage automatique) est une branche de l’IA qui permet aux systèmes informatiques d’apprendre des données météorologiques passées pour faire des prévisions plus précises ou identifier des motifs complexes.
Comment le machine learning peut-il prédire la pluie avec précision ?
En utilisant l’apprentissage supervisé, le modèle est entraîné sur des données météo passées et les quantités de pluie réelles associées. Il apprend ainsi à reconnaître les schémas qui mènent à la pluie, permettant des prévisions localisées à très court terme (nowcasting).
Quelle est la différence entre apprentissage supervisé et non supervisé pour la météo ?
L’apprentissage supervisé utilise des données avec des « bonnes réponses » (ex: quantité de pluie) pour prédire des valeurs. L’apprentissage non supervisé analyse des données sans réponses prédéfinies pour y découvrir des structures ou regrouper des types de temps (régimes météorologiques).
Comment l’apprentissage par renforcement est-il utilisé en météorologie ?
L’apprentissage par renforcement permet à un système d’apprendre par « essai-erreur » pour optimiser des décisions. En météo, cela pourrait concerner la gestion de ressources (eau, énergie) ou la planification logistique en fonction des prévisions, en maximisant des « récompenses » (économie, efficacité).
Le machine learning va-t-il remplacer les météorologues ?
Non, le machine learning ne remplace pas l’expertise humaine, mais agit comme un outil puissant. Il aide les météorologues à analyser d’énormes quantités de données, à affiner leurs prévisions et à détecter des phénomènes que l’œil humain ne verrait pas, « augmentant » ainsi leur travail.
Quels sont les défis du machine learning en prévision météo ?
Les défis incluent l’incertitude inhérente aux prévisions (probabilité vs. certitude), les biais potentiels des données (capteurs, couverture géographique), le coût énergétique de l’entraînement des modèles, et la nécessité de combiner le ML avec les modèles physiques traditionnels pour une précision optimale.
Le coût énergétique de l’IA est-il un problème pour la météo ?
Oui, entraîner des modèles de deep learning peut être très coûteux en énergie. Des pistes d’amélioration incluent l’allégement des modèles, l’utilisation de cloud alimenté par des énergies vertes, ou l’exécution sur des ordinateurs embarqués plus proches des capteurs.
Comment l’IA gère-t-elle l’incertitude dans les prévisions de pluie ?
Les modèles d’IA ne donnent jamais de certitude absolue, mais des probabilités ou des intervalles de confiance. C’est ensuite au décideur de transformer ce risque chiffré en action, en ajustant les seuils d’alerte selon le contexte (mieux vaut une fausse alerte que pas d’alerte en cas de danger).
Conclusion : demain, vers une météo augmentée
La météo, par sa complexité et sa richesse de données, sert de terrain d’essai pour l’apprentissage automatique. L’IA n’écarte pas le météorologue ; elle lui fournit des « lunettes intelligentes » pour voir plus vite, plus local et plus précis.
La prochaine fois que votre téléphone vibrera, souvenez‑vous : une IA a peut‑être passé en revue des millions de « parties » météo pour apprendre, pas à pas, à déjouer les caprices du ciel.

- Hallucinations d’IA – Quand les robots rêvent - 19 août 2025
- Pourquoi coopérer ? Le dilemme du prisonnier à l’épreuve de l’évolution - 1 août 2025
- Machine learning, quand l’IA regarde les nuages - 29 juillet 2025
Rejoignez-nous sur Instagram !
Découvrez nos infographies et astuces : @JeRetiensNet