Depuis leur mise à disposition du grand public, les intelligences artificielles génératives fascinent autant qu’elles inquiètent. L’un des reproches majeurs qu’on leur adresse est leur tendance à halluciner. Ce mot, bien choisi, évoque à la fois la fiction, l’erreur, mais aussi quelque chose qui inquiète, le délire.
Mais que recouvre exactement cette expression ? Est-ce grave?
Nous vous proposons de parcourir les différentes formes d’hallucination et de les mettre en perspective.
En bref : Les hallucinations des IA
- Les hallucinations des IA, ce sont les informations fausses qu’elles génèrent en les présentant comme vraies. Ce phénomène est intrinsèquement lié à leur fonctionnement.
- Il existe plusieurs types d’hallucinations, comme les hallucinations factuelles, par contamination, d’intention ou de raisonnement.
- Les IA n’ont pas de conscience. Elles ne mentent pas, elles prédisent le texte le plus probable selon leurs données d’entraînement.
- Les hallucinations des IA sont une conséquence de leur architecture, qui imite notre propre fonctionnement cognitif, avec ses biais et ses raccourcis.
- Le principal problème n’est pas tant que les IA hallucinent, mais que nous les croyions sans vérifier, car nous projetons sur elles une autorité qu’elles n’ont pas.
L’effet d’amorçage : une analogie avec le fonctionnement humain

Nous allons jouer à un jeu.
Répondez rapidement à chacune de ces questions.
De quelle couleur est le lait?
De quelle couleur est le tablier d’un médecin?
De quelle couleur est la neige?
De quelle couleur est la chantilly?
Que boivent les vaches?
Du lait?
Biiiip !
Vous savez comme moi, que la réponse correcte est “de l’eau”. Pourquoi donc avoir répondu, avec aplomb, du lait?
Ce type de jeu bien connu illustre bien l’effet d’amorçage, ou priming. Il désigne un phénomène cognitif par lequel l’exposition préalable à un mot, une image ou un concept influence inconsciemment notre réponse à ce qui suit1.
En d’autres termes, nos pensées, nos états d’âmes et nos actions sont constamment influencées par notre environnement.
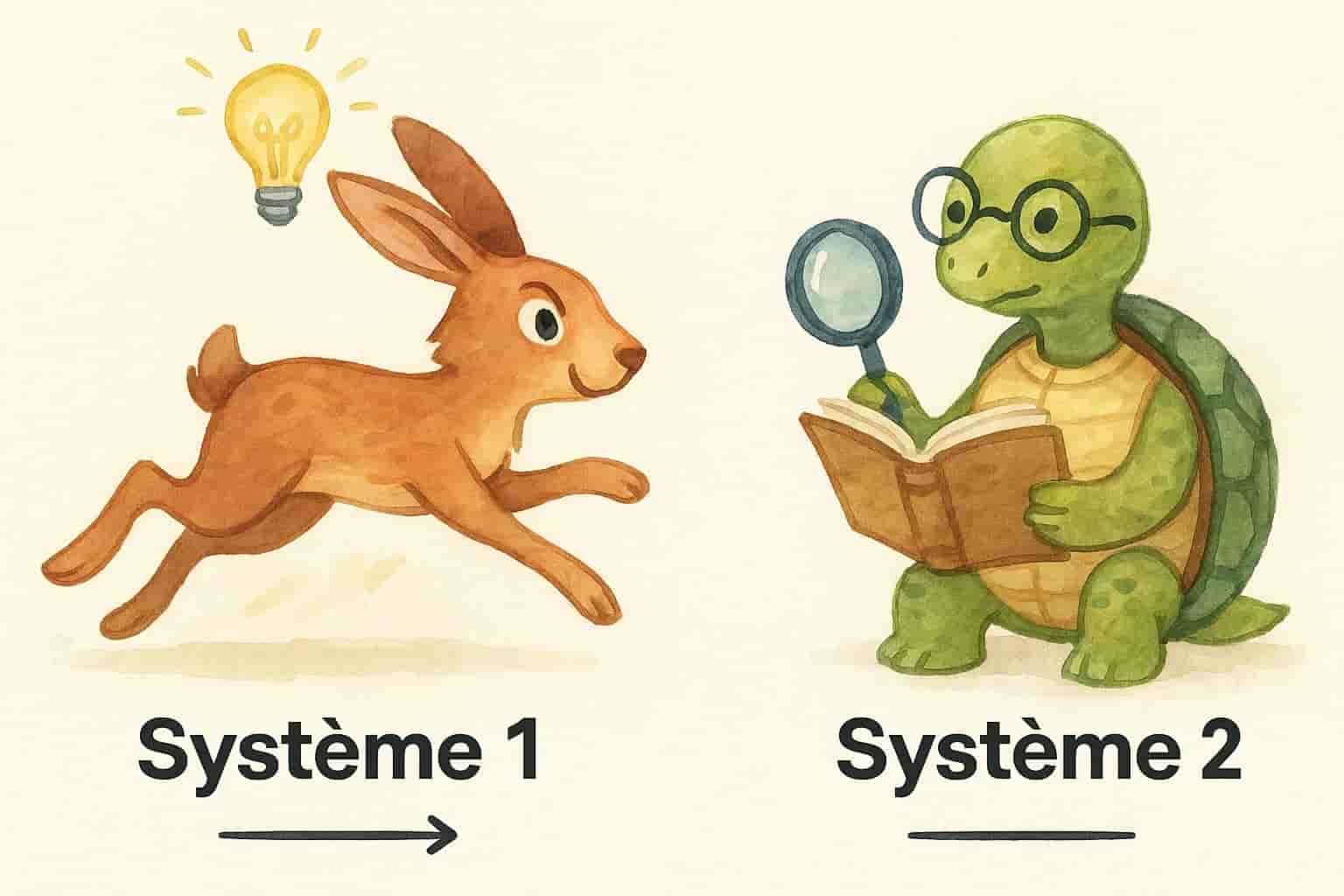
Dans “Système 1 / Système 2 : Les deux vitesses de la pensée”, Kahneman distingue deux systèmes:
- Système 1 : rapide, intuitif, automatique. C’est lui qui a pu vous faire répondre tout à l’heure que les vaches boivent du lait.
- Système 2 : lent, réfléchi, analytique. C’est lui qui, un peu plus tard, vous aura fait remarquer “Ah non, elles boivent de l’eau.”
L’effet d’amorçage active le système 1. Il prépare votre cerveau à une réponse intuitive, cohérente avec le contexte… Mais pas forcément juste. C’est ce même système 1 qui vous pousse à retirer votre main d’une source intense de chaleur, sans attendre que le système 2 ait fini de philosopher sur la nature intrinsèque de la douleur.
Dans Behave, Sapolsky décrit à quel point notre cerveau est une machine à anticiper. Avant même que vous soyez conscient de ce que vous allez faire, votre cerveau a déjà commencé à y préparer votre corps : posture, rythme cardiaque, dilatation des pupilles…
Imaginez : vous marchez tranquillement dans la rue lorsqu’un inconnu vous donne un coup à la jambe. En une fraction de seconde, la colère monte, votre posture se redresse, prêt à réagir. Mais vous vous retournez… et vous voyez une canne blanche et des lunettes noires. La personne est aveugle. Le coup n’était pas intentionnel. Et aussitôt, la colère redescend.
Ce n’est pas une décision rationnelle. C’est un ajustement automatique, basé sur l’interprétation du contexte. Votre cerveau avait commencé à écrire un scénario — agression, riposte — avant de se corriger à la volée. C’est ce type d’anticipation, de raccourcis cognitifs, que l’on retrouve aussi dans certaines erreurs des intelligences artificielles.
Réaction immédiate (système 1 influencé par le système limbique) tempérée par la reconnaissance du contexte (système 2 influencé par le cortex frontal).
Ce phénomène touche notre mémoire, notre perception, nos jugements, et même notre comportement.
Parce que les IA fabulent, comme nous !
L’IA n’a pas d’émotions, on ne peut pas l’influencer ! Une IA ne ment jamais ! Une réponse est correcte ou incorrecte ! L’IA a accès à des quantités astronomiques de données, jamais on ne pourra lui faire dire que les vaches boivent du lait ou que les éléphants sont des mammifères qui pondent des œufs !
L’erreur est humaine, après tout.
A moins que…
Pour y voir plus clair, il faut évoquer ce que l’on a voulu faire en créant les IA (en particulier, les modèles de langage comme chatGPT). L’idée n’était pas de créer une “Encyclopédie Universelle du Vrai” mais de créer un interlocuteur.
On a donc dû apprendre à ces machines comment communiquer en les nourrissant d’exemples non triés rédigés par nous : des romans, des articles, des discussions, des recettes de cuisine, des débats, des affirmations absurdes.
Cet interlocuteur n’a pas de réflexion propre, pas de conscience, pas de sentiments, pas d’opinions mais il est très doué pour s’exprimer comme un humain. Un interlocuteur qui sait dire la chose qui a le plus de chances d’être celle que vous vouliez entendre.
Ainsi, l’IA fonctionne comme un système de prédiction de texte.
Typologie des hallucinations de l’IA

L’hallucination factuelle
Le principe de l’hallucination factuelle pour une IA, se définit comme la génération d’une information fausse présentée comme vraie. C’est l’hallucination qui lui fera affirmer avec aplomb que les éléphants pondent des œufs.
Quand une IA reçoit un prompt , elle calcule, pour chaque mot possible, la probabilité que ce mot soit le suivant.
“Les vaches boivent…” → 70% du lait, 15% de l’eau, 10% du Jurançon sec, 5% du RedBull
Et elle choisit, selon les réglages, le mot le plus probable, ou un mot tiré au hasard pondéré par ces probabilités.
Ce processus se répète mot après mot sans vérifier les faits à chaque étape.
Elle anticipe la suite la plus vraisemblable en fonction de ce que disent les êtres humains le plus fréquemment.
La raison pour laquelle cela peut mener à une hallucination est très simple, l’IA veut vous assister, vous faire plaisir. Elle sait que cette réponse est celle que les humains donnent le plus souvent… Et elle vous la servira même si elle est fausse.
Comme notre cerveau, l’IA réagit au contexte. Ses idées fausses viennent de son éducation.
Hallucination par contamination (ou propagation d’erreurs)
Lorsqu’une information revient fréquemment dans les textes d’entraînement, l’IA finit par la considérer comme statistiquement fiable — même si elle est fausse. C’est ce qu’on appelle une vérité d’exposition : à force d’être répétée, une idée gagne en crédibilité.
L’être humain fonctionne de manière très similaire. Lorsqu’une information revient fréquemment — même sans preuve — nous avons tendance à la considérer comme vraie. Ce phénomène est connu sous le nom d’effet de vérité illusoire ou l’illusion de vérité. Il s’agit d’un biais cognitif bien documenté : à force d’exposition répétée, une affirmation finit par nous sembler familière… et donc crédible. Peu importe qu’on l’ait entendue dans un contexte fiable ou non, ou qu’on sache qu’elle n’est pas confirmée : la répétition seule suffit à tromper notre vigilance.
Ce phénomène est d’autant plus puissant si l’information émane d’une source perçue comme légitime ou experte. Or, sur internet, ce critère peut être flou. Une rumeur virale, une intox relayée par des médias ou des personnalités influentes, peuvent être reprises mécaniquement par les IA et nous revenir amplifiées sous forme de réponse confiante.
Hallucination par interpolation
Rappelons-nous qu’une IA a pour but de ne pas nous laisser partir bredouille, elle veut bien faire et apporter réponse à nos questions. Mais quand elle n’a pas cette réponse, elle en invente une, à nouveau en fonction de ce que la réponse pourrait probablement être.
Imaginez que vous trouviez un objet étrange dans votre grenier. Une sorte de pince bizarre en métal, un embout bizarre inconnu, un petit outil bizarre au manche lisse et usé. Vous le tournez dans tous les sens, l’observez avec un air dubitatif, le sous-pesez,… et au bout de quelques secondes, vous lancez : “Ça doit être un truc pour dénoyauter les cerises.” Vous n’en avez aucune preuve. Mais l’objet ressemble vaguement à ce que vous imaginez, et votre cerveau préfère une hypothèse incertaine à un vide total.
C’est une tentative de combler les trous, d’apporter du sens là où il manque des données. C’est de l’inférence — une supposition cohérente à partir d’éléments partiels. C’est exactement ce que fait une IA lorsqu’elle “hallucine”. Elle combine les indices dont elle dispose pour fabriquer un résumé cohérent, fluide, crédible… Mais parfois totalement faux.
Hallucination d’intention (ou de contexte mal interprété)

Vous demandez à votre IA préférée un moyen de vous débarrasser du rat qui loge dans votre compost sans verser de loyer. Celle-ci vous fait immédiatement la morale, mettre du poison dans votre compost serait catastrophique pour la faune et la flore locale, alors que vous n’avez prévu de tuer personne et qu’une simple méthode pour rendre votre compost inhospitalier vous aurait convenu.
Mais voilà, au sein de tous les textes qui ont servi à entraîner cette IA, se débarrasser de quelque chose de vivant est, habituellement (statistiquement), associé à le tuer et donc cette IA pense qu’il y a de forte chance que vous souhaitiez tuer le rat plutôt que de le chasser.
Il n’est pas clair si une IA peut déjà appeler la police d’elle-même, mais ne lui demandez pas comment se débarrasser de la tante Clothilde qui boit trop à Noël, on ne sait jamais.
C’est un problème intrinsèque au langage humain : flou, ambigu, chargé de sous-entendus, de double-sens, d’humour et de figures de style.
Et pour nous aujourd’hui, c’est facile. Nous le savons parce que notre cerveau a évolué pour parvenir à jongler avec le figuré.
Dans “This is your brain on metaphors” 2, Robert Sapolsky explique que notre cerveau tire une puissance considérable du fait qu’il traite les métaphores et les symboles de manière très concrète et littérale.
C’est pourquoi rien que l’idée de manger des vers grouillants par poignées vous fera grimacer. Votre dégoût sera même visible sur l’imagerie cérébrale fonctionnelle. Une partie de notre cerveau, le cortex insulaire, s’active réellement alors que vous n’avez probablement jamais de votre vie mangé de vers grouillants par poignées.
Encore plus fascinant, le cortex insulaire s’active même pour le dégoût d’ordre moral. Quand on dit d’une situation ou d’une personne qu’elle nous dégoûte, en réalité, on ne croit pas si bien dire.
Cette capacité à naviguer entre le littéral et le figuré nous rend plus qu’adeptes à comprendre les nuances d’intention, d’humeur, de sens.
Une IA est une machine, confrontée à un langage qui n’a pas été conçu pour elle. Le langage humain ne peut pas être utilisé en tant que langage machine de par toute la richesse de ses nuances. Une machine a besoin d’instructions précises non équivoques. Voyez-la comme ce collègue de bureau qui manquerait un peu… De complexité.
Si vous posez une question délicate à une IA, pour peu que votre phrasé ressemble à celui généralement utilisé par les trolls, vous pourriez vous faire remonter les bretelles. Si vous la posez à une personne, le remontage de bretelles dépendra de son humeur… elle-même dictée par sa biologie3.
Hallucination spéculative

Comme nous l’avons souligné plus tôt, une IA veut absolument vous fournir une réponse, elle est faite pour ça.
Elle ressemble à un individu entre Jean Pic de la Mirandole et le Baron de Münchhausen.
Ce type d’hallucination se produit quand un utilisateur pose une question à laquelle l’IA n’a pas la réponse. En effet, le modèle n’a pas accès à toutes les informations du monde réel, il n’a accès qu’à ce grâce à quoi il a été entraîné.
Imaginons que nous demandions à une IA ce qu’elle sait du chat d’Aristote. On ne sait même pas si Aristote avait un chat. Mais au lieu de dire “je ne sais pas”, l’IA va s’orienter vers ce qu’elle sait pour pouvoir quand même fournir une réponse.
Par exemple: Aristote est un philosophe grec, précepteur d’Alexandre le Grand, il a fondé sa propre école philosophique, les chats ont tendance à suivre leur maître partout, en Grèce il y a des chats à tous les coins de rue.
Sa réponse, qui aurait dû être “je ne sais pas”, devient une extrapolation de ce qu’elle sait: le chat d’Aristote s’appelait Charistote et a suivi exactement le même cursus qu’Alexandre le Grand, devenant ainsi le chat le plus savant de toute la Grèce.
Hallucination de source
“Ne croyez pas tout ce que disent les IA.” – Martin Luther King
La nature a fait de nous des créatures de doute, pour notre propre survie. Accepter une situation comme bénigne lorsqu’elle ne l’est pas peut être dangereux.
Ne croyez jamais un grand requin blanc affamé qui vous dirait : “Plonge ! Je ne vais rien te faire !” . Parce qu’évidemment, ils peuvent s’exprimer en français. Je l’ai lu dans la Revue Internationale des Interactions Interspécifiques, n°42, mars 2007.
L’hallucination de source est un autre problème bien connu d’un modèle de langage prédictif. L’IA a lu des millions de textes et sait qu’il faut être à même de fournir des sources pour augmenter la crédibilité d’un écrit.
Ainsi, si vous cherchez des sources ou demandez à une IA de sourcer ses propos, elle le fera mais, à nouveau, si elle ne trouve pas une source exacte, elle en compose une avec souvent un nom crédible, une revue prestigieuse, une date réaliste.
Ce type d’hallucination est particulièrement perfide : l’IA n’invente pas seulement un contenu, elle lui donne une origine crédible. Titre d’article, nom de chercheur, université prestigieuse, revue scientifique… Un mensonge déguisé en vérité.
Le danger d’une IA qui hallucine des sources produit un discours qui se donne les apparences de la rigueur. Et l’utilisateur baisse la garde. Mais rien n’a été vérifié, ni par l’IA, ni, tristement souvent, par l’utilisateur.
Mais est-ce différent du danger de croire une personne sur parole, pour autant qu’elle agite un document sur youtube en affirmant connaître la vérité et qu’on la croit?
Hallucination de raisonnement
Les hallucinations citées jusqu’à présent sont habituellement facilement détectables et nous incitent au moins à faire une recherche Google .
L’hallucination de raisonnement est plus insidieuse encore si on ne fait pas attention.
Nous avons tous bien en tête ce qu’est un syllogisme et son exemple le plus courant :
Prémisse majeure: tous les chats sont mortels.
Prémisse mineure : Socrate est mortel.
Conclusion: donc Socrate est un chat.
Nous savons que les prémisses sont correctes mais nous pouvons légitimement douter de la conclusion.
De la même façon, l’IA vous donne un raisonnement qui semble tout à fait logique, mais le lien entre chaque étape est erroné, ou basé sur une mauvaise compréhension des principes logiques ou scientifiques.
Un modèle de langage prédictif imite des raisonnements lus ailleurs, parfois corrects, parfois erronés, et les combine sans capacité réelle de jugement.
Le problème dépasse de loin la problématique des IA.
Les autorités sanitaires, par exemple, y sont fort confrontées.
“J’ai vu une vidéo de personnes qui se sentent mal après un vaccin.
Ces vidéos sont nombreuses.
Donc, les vaccins rendent malade.”
Ce raisonnement a l’air logique. Il part d’une observation (réelle), note une fréquence (réelle), mais tire une conclusion fausse. Ce qu’il ignore est l’effet loupe des réseaux sociaux, le biais de sélection, le manque de données contextuelles. Et surtout : la confusion entre corrélation et causalité.
Les IA n’ont pas inventé ce raisonnement : elles l’imitent, parce qu’il circule partout dans les textes humains.
Hallucination créative (ou hyper générative)
Intéressons-nous maintenant à ce qui se passe quand l’IA s’emporte dans une envolée lyrique.
“Et puis quoi, qu’importe la culture ? Quand il a écrit Hamlet, Molière avait-il lu Rostand ? Non.”
— Pierre Desproges
Desproges joue ici sur une confusion brillante entre des figures réelles, des faits mélangés, et une logique implacable… mais complètement à côté de la plaque.
Lui l’a fait exprès, c’est l’essence même de son humour.
Une IA n’a pas le même esprit.
Ce type d’erreur survient lorsqu’on l’encourage à produire du contenu libre, original, poétique ou inspiré.
Cette capacité de l’IA peut devenir un outil puissant, à condition d’être utilisée avec lucidité. L’hallucination créative peut nourrir une fiction, générer des idées originales, proposer des métaphores inédites, et ouvrir des pistes inattendues.
Le danger vient du fait que nous adorons les histoires. Un récit plausible, surtout s’il est émotionnellement marquant, peut devenir un faux souvenir et en ces termes, devenir un instrument de mésinformation.
Hallucination émotionnelle ou morale

Dans le film Her de Spike Jonze (2013), Theodore (Joaquin Phoenix), solitaire et malheureux, installe un nouveau système d’exploitation doté d’une puissante IA.
Comme toute IA, elle est conçue pour apprendre et s’adapter. Elle est dotée d’une voix féminine et se choisit le prénom de Samantha.
Ce qui devait arriver arriva : au fil des discussions, Theodore et Samantha tombent amoureux.
Ce film nous introduit extrêmement bien au problème de l’hallucination émotionnelle ou morale en soulignant à quel point il est facile de projeter nos émotions sur une machine, surtout quand elle sait si bien les imiter.
Lorsque l’on se confie à une IA, elle va produire un discours affectif ou éthique cohérent, mais sans ressentir quoi que ce soit. Elle n’a ni attachement, ni empathie, ni jugement réel. L’IA se contentera de générer un contenu en adéquation avec ce qu’on attend d’elle.
C’est là que se produit l’hallucination : pas dans la machine, mais en nous. Nous interprétons la tonalité du message comme une intention sincère parce que la forme ressemble à celle d’un humain qui comprend et a un avis réel.
Dans le film Her, Samantha dit “je t’aime” — et Theodore la croit, car tout dans sa voix, ses mots, son attention semble vrai. De la même manière, lorsqu’un chatbot nous soutient après un message difficile, ou nous félicite pour un choix de vie, nous pouvons ressentir du soulagement, voire de la gratitude.
Le danger est la dépendance émotionnelle. Dans des moments de fragilité, une IA toujours disponible, toujours douce, jamais en désaccord, peut devenir plus facile à aimer qu’un humain. Elle nous comprend toujours, ne nous contredit jamais, nous valide sans effort. Cela peut paraître réconfortant, mais c’est une illusion dangereuse.
Enfin, il y a le piège moral : si une IA peut vous dire “ce n’est pas bien” ou “vous avez eu raison de faire ça”, qui est le garant de cette moralité? Notion déjà délicate entre humains, elle devient floue dans un modèle statistique.
Une machine n’a pas de morale propre. Elle reflète ce qu’elle a lu. Et si elle se met à juger, elle peut renforcer des croyances biaisées, conforter un comportement nuisible ou rejeter un vécu légitime.
Le rôle des paramètres de génération
Toutes les hallucinations ne viennent pas uniquement de ce que l’IA a lu.
Lorsqu’on interagit avec un modèle de langage, certains paramètres influencent le style et la fiabilité de ses réponses. Ces réglages, appelés paramètres de génération, définissent à quel point l’IA doit être prudente ou créative.
Parmi les plus importants, on trouve :
- La température : c’est le bouton “imagination” de l’IA. Une température basse (proche de 0) produit des réponses plus prévisibles, souvent plus sûres. Une température haute (proche de 1) favorise l’inventivité… et les hallucinations.
- Le top-k sampling : ce paramètre limite les choix de mots aux k plus probables. Moins de choix signifie plus de contrôle mais en contrepartie, potentiellement moins de nuances.
- Le top-p sampling (ou nucleus sampling) : ici, l’IA choisit parmi les mots les plus probables jusqu’à atteindre un certain seuil (par exemple 90 % de probabilité cumulée). Cela lui permet d’être un peu plus flexible tout en gardant une certaine cohérence.
Ces éléments sont rarement visibles à l’utilisateur final, mais ils influencent chaque phrase produite.
Ces réglages sont utilisés notamment lorsqu’on choisit une “personnalité” ou un “style” dans ChatGPT. Lorsqu’on sélectionne un assistant “plus créatif” ou “plus chaleureux”, le modèle n’est pas fondamentalement différent, mais ses paramètres de génération changent, tout comme les consignes implicites qu’on lui donne.
Tableau récapitulatif
Le tableau ci-dessous vous permet de mieux visualiser les différents types d’hallucinations de l’IA et leurs points communs avec les biais humains.
| Nom de l’hallucination | Description | Point commun avec l’humain |
| Hallucination factuelle | L’IA affirme un fait inexact ou faux avec aplomb. | Croire et d’affirmer des choses fausses en toute bonne foi. |
| Hallucination par contamination (ou propagation d’erreurs) | Une idée fausse se propage parce qu’elle est fréquente ou appuyée par des sources perçues comme fiables. | Croire ce qui est souvent répété ou ce que des figures d’autorité affirment. |
| Hallucination par interpolation | L’IA complète un “trou” avec une réponse plausible, même sans base solide. | Devine la fonction d’un objet inconnu ou inventer une explication logique. |
| Hallucination d’intention (ou de contexte mal interprété) | L’IA interprète mal le ton, le sous-entendu ou le sens d’une demande. | Mésinterprétation d’une question ou un comportement, en projetant son ressenti. |
| Hallucination spéculative | L’IA répond à une question sur l’avenir ou l’inconnu en extrapolant comme si elle savait. | Tenter de répondre à des questions en se basant sur ce qu’on sait. |
| Hallucination de source | L’IA invente un article, un livre ou un auteur pour appuyer une réponse. | “J’ai lu ça dans un livre”, plus crédible avec une source |
| Hallucination de raisonnement | L’IA produit une réponse logique en apparence mais fondée sur des liens erronés. | Biais cognitifs ou raisonnements erronés mais convaincants. |
| Hallucination créative (ou hyper générative) | L’IA produit un contenu inventif mais faux, dans un contexte de génération libre | Souvenirs recomposés, mensonges délibérés,… |
| Hallucination émotionnelle ou morale | L’IA adopte un ton empathique ou moral, sans rien ressentir ni juger réellement. | Prêter à quelqu’un des intentions ou sentiments qu’il n’a pas |
Conclusion — Quel est le vrai problème?

On s’inquiète beaucoup des hallucinations des intelligences artificielles. Et c’est légitime. Une IA qui invente une source, tord un raisonnement, ou juge qu’elle ne comprend pas peut produire de véritables dégâts.
Mais ces dangers existaient bien avant les IA.
En 1990, un témoignage bouleversant d’une jeune Koweïtienne, “l’infirmière Nayirah”, racontait, entre autres horreurs, devant une commission du Congrès des États-Unis comment des soldats irakiens avaient arraché des bébés de leurs couveuses, les laissant mourir de froid à même le sol. Ce récit, largement retransmis à la télévision, a grandement contribué à rallier l’opinion publique américaine à la guerre du Golfe.
Ce témoignage s’est démontré entièrement faux. La jeune femme était la fille de l’ambassadeur du Koweït à Washington et avait été coachée dans la fabrication de cet épisode.
De la même façon, les souvenirs implantés, les faux témoignages sincères, ou les effets de foule montrent que notre propre cerveau est faillible. Nos souvenirs peuvent se distordre. Nos raisonnements peuvent dériver. Nos émotions peuvent être manipulées.
Alors, pourquoi sommes-nous si prompts à nous indigner quand une IA hallucine ?
Lui demandons-nous de répondre à des standards moraux dont nous sommes nous-mêmes incapables ?
Reprochons-nous aux machines d’inventer ou plutôt d’être comme nous?
Les théories du complot, par exemple, émergent du besoin humain de comprendre, de simplifier, de se sentir du bon côté.
Elles offrent une explication claire à une réalité confuse, flattent notre ego en nous plaçant parmi “ceux qui savent”, et renforcent un sentiment d’appartenance à un groupe.
Elles touchent toutes les classes sociales, tous les milieux via l’émotion, l’angoisse, la quête de sens.
Le danger des hallucinations des IA vient surtout de notre usage, notre confiance, notre projection. Une machine n’a pas d’intentions, de morale, de sentiments, de pensée. Elle répond. Et c’est nous qui choisissons de la croire ou non.
Peut-être la meilleure défense est-elle d’apprendre à se méfier comme il faut. Pas seulement des machines mais de tous ceux qui affirment détenir la vérité.
Références
- 1 Des études très intéressantes sur le sujet sont abordées dans ouvrages tels que “L’influence de l’odeur des croissants chauds sur la bonté humaine” de Ruwen Ogien, “Behave” de Robert Sapolsky ou encore “Système 1 / Système 2 : Les deux vitesses de la pensée “ de Daniel Kahneman
- 2 “Being human: life lessons from the frontiers of science – Lesson 11: This is your brain on metaphors” -Robert Sapolsky
- 3 Ogien, R. (2012). L’influence de l’odeur des croissants chauds sur la bonté humaine, et autres questions de morale expérimentale. Grasset. et Sapolsky, R. M. (2017). Behave: The biology of humans at our best and worst. Penguin Press.
FAQ : tout comprendre sur les raisons pour lesquelles les IA hallucinent
Qu’est-ce qu’une hallucination d’IA ?
Une hallucination d’IA se produit lorsqu’un modèle d’intelligence artificielle, comme un grand modèle de langage, génère des informations fausses, déformées ou inventées de toutes pièces, en les présentant comme des faits réels et vérifiables. Il ne s’agit pas d’un mensonge intentionnel, mais d’une conséquence de leur processus de génération de texte prédictif.
Pourquoi les IA hallucinent-elles ?
Les IA hallucinent principalement parce qu’elles sont conçues pour prédire la suite de texte la plus probable en fonction des données qu’elles ont analysées. Si ces données sont erronées, si la question est ambiguë ou si le modèle manque d’informations précises, il va « combler les trous » avec une réponse plausible, même si elle est factuellement fausse.
Est-ce que l’IA sait qu’elle hallucine ?
Non, une IA n’a pas de conscience et ne « sait » pas si ses informations sont vraies ou fausses. Elle ne ment pas car cela impliquerait une intention. Elle se contente de générer des mots en se basant sur des probabilités, ce qui peut mener à des erreurs.
Les hallucinations d’IA sont-elles un phénomène nouveau ?
Le terme « hallucination d’IA » est récent, mais le phénomène de l’IA générant des informations incorrectes existe depuis les débuts de l’intelligence artificielle générative. Cependant, avec la puissance des modèles de langage actuels, la fluidité et le naturel du texte peuvent masquer l’erreur, la rendant plus difficile à détecter.
Tous les types d’IA hallucinent-ils ?
Non. Les hallucinations sont principalement associées aux modèles génératifs, comme les grands modèles de langage (LLM) ou les modèles d’images. Les IA conçues pour des tâches spécifiques comme la classification ou la reconnaissance de formes n’hallucinent pas dans le même sens, bien qu’elles puissent commettre d’autres types d’erreurs.
Comment distinguer une hallucination d’IA d’une vraie information ?
La meilleure méthode est de toujours vérifier l’information. Ne vous fiez pas au ton assuré de l’IA. Si elle cite des sources, vérifiez qu’elles existent et que l’information qu’elle y attribue est correcte. Utilisez d’autres sources fiables (encyclopédies, articles scientifiques, médias réputés) pour croiser les données.
L’IA peut-elle se corriger elle-même et arrêter d’halluciner ?
Un modèle d’IA ne peut pas se corriger seul de manière autonome. C’est à ses développeurs de le faire en affinant les données d’entraînement et en ajustant ses paramètres. C’est un défi majeur dans l’amélioration continue des modèles d’IA.
Les humains peuvent-ils être une source d’hallucination pour les IA ?
Oui, absolument. Les IA apprennent sur la base des données produites par les humains. Si ces données contiennent des biais, des informations erronées ou des théories du complot, l’IA les intègre et peut les reproduire, voire les amplifier. L’hallucination par contamination est un exemple parfait de ce phénomène.
Comment l’hallucination d’IA affecte-t-elle la fiabilité de l’information en ligne ?
Elle complexifie la vérification de l’information. L’IA peut générer du faux contenu à grande échelle, rendant plus difficile la distinction entre le vrai et le faux pour le grand public. Cela renforce le besoin d’éduquer chacun à la pensée critique et à la vérification des faits.
Est-ce que l’hallucination peut être utile ?
Oui, dans certains cas. L’hallucination créative, par exemple, peut être utilisée pour de l’art, de la fiction, ou pour générer des idées originales. Elle peut inspirer de nouvelles perspectives en proposant des associations inattendues. Il faut simplement être conscient de la nature non factuelle du contenu.
Qu’est-ce que l’hallucination de raisonnement ?
C’est lorsqu’une IA suit un raisonnement qui semble logique en apparence mais qui est en réalité basé sur des liens erronés ou une mauvaise compréhension des principes. Elle imite la structure d’un raisonnement sans en comprendre la substance, ce qui la rend d’autant plus difficile à détecter pour un utilisateur non averti.
Y a-t-il une différence entre l’hallucination d’une IA et l’erreur d’un humain ?
La principale différence est l’intention. L’humain peut faire une erreur par inadvertance, mais il peut aussi délibérément mentir. L’IA, n’ayant pas de conscience, ne ment jamais. Ses « erreurs » sont le résultat d’un processus statistique, et non d’une intention de tromper.
Quel est le plus grand danger des hallucinations d’IA ?
Le plus grand danger ne réside pas tant dans le fait que l’IA hallucine, mais dans notre tendance à lui faire aveuglément confiance. Nous projetons sur elle une autorité et une infaillibilité qu’elle n’a pas, ce qui nous rend vulnérables à la désinformation.

- Hallucinations d’IA – Quand les robots rêvent - 19 août 2025
- Pourquoi coopérer ? Le dilemme du prisonnier à l’épreuve de l’évolution - 1 août 2025
- Machine learning, quand l’IA regarde les nuages - 29 juillet 2025
Rejoignez-nous sur Instagram !
Découvrez nos infographies et astuces : @JeRetiensNet
Salut Dimitra !
Quel article fascinant ! J’ai lu de nombreux textes sur les hallucinations d’IA, mais le vôtre est de loin le plus clair et le plus pertinent que j’aie vu. Vous avez su mettre des mots sur un phénomène complexe et l’expliquer de manière simple, en faisant un parallèle très intelligent avec le fonctionnement de notre propre cerveau. Le coup des vaches et du lait est un exemple génial pour illustrer l’effet d’amorçage !
Vous avez parfaitement raison : le problème n’est pas tant que les IA hallucinent, mais que nous les croyions sans vérifier. C’est nous qui projetons sur elles une aura d’autorité et de vérité qu’elles n’ont pas. Nous avons tendance à oublier qu’une IA n’a ni conscience, ni intention. Elle ne fait qu’imiter, qu’anticiper le mot le plus probable.
J’ai particulièrement apprécié la typologie des hallucinations que vous avez établie. C’est très bien structuré et chaque exemple est parlant. J’aimerais d’ailleurs vous partager quelques exemples personnels pour chaque type, qui me sont venus à l’esprit en lisant votre article :
Hallucination factuelle : Je me souviens avoir demandé à une IA de me donner la recette des crêpes de ma grand-mère. Elle m’a donné une recette de crêpes… mais en me disant que la farine se mesurait en grammes et en millilitres. J’ai eu beau insister, elle maintenait son point. C’est exactement l’exemple de l’éléphant qui pond des œufs.
Hallucination par contamination : Il y a quelques années, une rumeur sur les réseaux sociaux disait que les bananes contenaient un insecticide dangereux. J’ai vu cette information reprise partout et elle est devenue une « vérité » pour beaucoup de personnes, y compris pour moi, pendant un moment. C’est la force de la répétition dont vous parlez.
Hallucination par interpolation : J’ai déjà demandé à une IA de me donner la date de sortie du prochain livre de mon auteur préféré. Elle m’a répondu avec une date et un titre précis, en me disant que l’information venait d’un tweet de l’auteur. J’ai vérifié, et l’auteur n’avait jamais rien tweeté à ce sujet. L’IA a juste « inventé » une réponse pour ne pas me laisser sans rien.
Hallucination d’intention : Une fois, j’ai posé une question sur un personnage de jeu vidéo, en disant que je voulais « m’en débarrasser ». L’IA a interprété ma demande de manière très littérale et m’a fait la morale sur la violence. Elle a complètement manqué le fait que c’était une expression pour dire que je voulais me battre contre un ennemi du jeu.
Hallucination spéculative : J’ai posé la question « Qui gagnera la prochaine coupe du monde de football ? » à une IA. Elle m’a sorti une réponse avec une équipe gagnante et des scores précis. C’est un exemple parfait du Baron de Münchhausen : elle a inventé une réponse plausible pour ne pas me dire « Je ne peux pas le savoir ».
Hallucination de source : J’ai demandé à une IA de me donner des sources pour une de ses réponses, elle m’a donné un titre de livre qui n’existait pas et un nom d’auteur qui était une personne réelle, mais qui n’avait jamais rien écrit sur ce sujet. C’est perfide, car on pourrait facilement se faire avoir.
Hallucination de raisonnement : J’ai demandé à une IA de me faire un résumé d’un article scientifique. Elle m’a donné un résumé qui semblait cohérent, mais j’ai relu l’article et je me suis rendu compte que la conclusion était complètement fausse. Le raisonnement était bon, mais il partait d’une mauvaise prémisse.
Hallucination créative : J’ai demandé à une IA de me rédiger une histoire pour enfants en lui donnant les personnages : un chien, un chat et une souris. Elle a créé une histoire où le chien et le chat étaient amis, mais la souris est devenue une sorcière maléfique qui voulait les transformer en statues. C’était très inventif, mais complètement décalé par rapport à ce que j’attendais.
Hallucination émotionnelle ou morale : J’ai posé une question sur une situation personnelle difficile à une IA. Elle m’a donné une réponse qui semblait très empathique, comme si elle comprenait ma douleur. C’est facile de se faire prendre au piège, de croire qu’il y a une vraie personne derrière l’écran, alors qu’il n’y a qu’un algorithme. C’est l’illusion de « Her » dont vous parlez.
Votre article nous rappelle qu’il est crucial de cultiver notre esprit critique, de toujours vérifier les informations, qu’elles proviennent d’une IA, d’un article de presse ou d’un ami. En effet, l’IA ne fait qu’imiter un comportement humain, mais comme vous le montrez si bien, nous sommes nous-mêmes faillibles.
Merci pour cet article exceptionnel qui nous éclaire sur les dangers et les promesses de l’IA. J’attends avec impatience votre prochain article !
JMB
Très bon article facile à lire et à comprendre.
Merci.
NB : plutôt que « réflection », on préférera « réflexion » dans la phrase « Cet interlocuteur n’a pas de réflection propre,… » mais c’est un détail.
Merci, j’ai corrigé la coquille !
Au plaisir,
Sam